
HPC ≠ HARDWARE
High Performance Computing is a function of state of the art Hardware that enables electrons to move around as close to speed of light as possible AND Software that can leverage the hardware to the fullest potential
WHY ROCKETML HPC
Time to Solution
Deep Learning is a key part of modern product development - Accelerate innovation and time to solution with RocketML.
Shorten training times, experiment more
RocketML HPC software infrastructure is highly scalable, saving both time and cost.
No labels? No problems
RocketML HPC software infrastructure supports all types of modern frontier Deep Learning methods, ranging from Fully Supervised Learning to Semi-Supervised, Self-Supervised, Weak-Supervised, and Unsupervised.
lowest TCO on cloud
Unlike Horovod, a most commonly used distributed deep learning framework, increasing batch sizes won't deteriorate convergence on RocketML, enabling better run times, accuracies and in turn more than 50% in cost savings.
EXPERIENCE THE POWER OF HPC ON CLOUD
Azure HPC cloud Infrastructure
Azure H-series and N-series VMs comes with InfiniBand, which ensures optimized and consistent RDMA performance.
RocketML HPC Machine Learning
Highly scalable Distributed Deep Learning software framework for large models, large data and big compute.
DEMOCRATIZE HPC
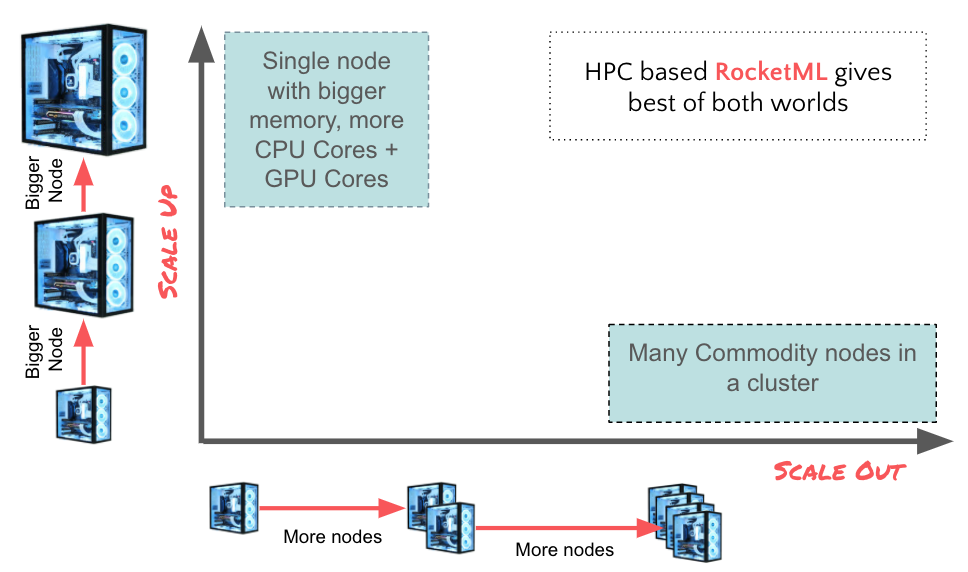
The use of high performance computing ( HPC ) has contributed significantly and increasingly to scientific progress, industrial competitiveness, national and regional security, and the quality of human life. However, due to its complexity, its use has been limited to trained HPC engineers. RocketML intends to change that by abstracting the complexities and enabling ALL Scientists including Data Scientists to benefit from HPC value proposition. On RocketML, engineers and scientist can scale both vertically (bigger machines) and horizontally (more machines in parallel) by just a click of button for both high throughput and tightly coupled HPC workloads.
NO HPC SKILLS REQUIRED
All the HPC complexities (like MPI, Job Schedulers) are abstracted without compromising performance.
No Cloud Skills required
Scientists can spin up clusters on web based UI without logging into Cloud consoles.
HPC Frequently asked Questions
Supercomputers are the best known type of HPC solution. High-performance computing (HPC) is the ability to process data and perform complex calculations at high speeds utilizing multiple compute nodes. In order to get best out of a cluster of computer, Software has to be tuned to perform on the entire cluster vs. just single machine. Software is often the unsung hero in getting the best out of the expensive hardware. It is truly the biggest value generator in most data centers. RocketML brings HPC software to Machine Learning on Cloud.
Machine learning is computationally intensive. As data increases and number of parameters grow, the memory footprint as well as computational capacity required to solve a problem grows exponentially. This massive demand for compute infrastructure, if not satisfied via HPC, will cause each iteration of ML run to become super slow (days and weeks instead of minutes) leading to opportunity cost, loss of productivity and ultimately unfinished projects. HPC speeds up these iterations and experimentation by orders of magnitude – enabling novel discoveries and reduced Time to Solution
HPC or supercomputing environments address large and complex challenges with individual nodes (computers) working together in a cluster (connected group) to perform massive amounts of computing in a short period of time. Creating and removing these clusters is often automated in the cloud to reduce costs.
HPC can be run on many kinds of workloads, but the two most common are embarrassingly parallel workloads and tightly coupled workloads.
- Embarrassingly parallel workloads are computational problems divided into small, simple, and independent tasks that can be run at the same time, often with little or no communication between them. Common use cases include risk simulations, molecular modeling, contextual search, and logistics simulations.
- Tightly coupled workloads typically take a large shared workload and break it into smaller tasks that communicate continuously. In other words, the different nodes in the cluster communicate with one another as they perform their processing. Common use cases include computational fluid dynamics, weather forecast modeling, material simulations, automobile collision emulations, geospatial simulations, and traffic management
HPC can be performed on premise, in the cloud, or in a hybrid model that involves some of each.
In an on-premise HPC deployment, a business or research institution builds an HPC cluster full of servers, storage solutions, and other infrastructure that they manage and upgrade over time. In a cloud HPC deployment, a cloud service provider administers and manages the infrastructure, and organizations use it on a pay-as-you-go model.
Some organizations use hybrid deployments, especially those that have invested in an on-premise infrastructure but also want to take advantage of the speed, flexibility, and cost savings of the cloud. They can use the cloud to run some HPC workloads on an ongoing basis, and turn to cloud services on an ad hoc basis, whenever queue time becomes an issue on premise.
All cloud providers are not created equal. Some clouds are not designed for HPC and can’t provide optimal performance during peak periods of demanding workloads. The four traits to consider when selecting a cloud provider are
- Leading-edge performance: Your cloud provider should have and maintain the latest generation of processors, storage, and network technologies. Make sure they offer extensive capacity and top-end performance that meets or exceeds that of typical on-premise deployments.
- Experience with HPC: The cloud provider you select should have deep experience running HPC workloads for a variety of clients. In addition, their cloud service should be architected to deliver optimal performance even during peak periods, such as when running multiple simulations or models. In many cases, bare metal computer instances deliver more consistent and powerful performance compared to virtual machines.
- Flexibility to lift and shift: Your HPC workloads need to run the same in the cloud as they do on premise. After you move workloads to the cloud “as is” in a lift-and-shift operation, the simulation you run next week must produce a consistent result with the one you ran a decade ago. This is extremely important in industries where year-to-year comparisons must be made using the same data and computations. For example, the computations for aerodynamics, automobiles, and chemistry haven’t changed, and the results cannot change either.
- No hidden costs: Cloud services are typically offered on a pay-as-you-go model, so make sure you understand exactly what you’ll be paying for each time you use the service. Many users are often surprised by the cost of outbound data movement, or egress—you may know you have to pay per transaction and for data access requests, but egress costs are easily overlooked.
Getting the results you expect and want
Generally, it’s best to look for bare metal cloud services that offer more control and performance. Combined with RDMA cluster networking, bare metal HPC provides identical results to what you get with similar hardware on premise.
Nearly every industry employ HPC, with a large range of problems typified by the following:
- Biochemistry: Protein-folding attempts to determine the overall shape of a protein based on the sequence of amino acids; Refining computational models allows new medicines to be developed more efficiently.
- Aerospace: Creating complex simulations, such as airflow over the wings of planes
- Manufacturing: Executing simulations, such as those for autonomous driving, to support the design, manufacture, and testing of new products, resulting in safer cars, lighter parts, more-efficient processes, and innovations
- Financial technology (fintech): Performing complex risk analyses, high-frequency trading, financial modeling, and fraud detection
- Genomics: Sequencing DNA, analyzing drug interactions, and running protein analyses to support ancestry studies
- Healthcare: Researching drugs, creating vaccines, and developing innovative treatments for rare and common diseases
- Media and entertainment: Creating animations, rendering special effects for movies, transcoding huge media files, and creating immersive entertainment
- Oil and gas: Performing spatial analyses and testing reservoir models to predict where oil and gas resources are located, and conducting simulations such as fluid flow and seismic processing
- Retail: Analyzing massive amounts of customer data to provide more-targeted product recommendations and better customer service
- Physics
- Environment Modeling
- Industry
HPC has been a critical part of academic research and industry innovation for decades. HPC helps engineers, data scientists, designers, and other researchers solve large, complex problems in far less time and at less cost than traditional computing.
The primary benefits of HPC are
- Reduced physical testing: HPC can be used to create simulations, eliminating the need for physical tests. For example, when testing automotive accidents, it is much easier and less expensive to generate a simulation than it is to perform a crash test.
- Speed: With the latest CPUs, graphics processing units (GPUs), and low-latency networking fabrics such as remote direct memory access (RDMA), coupled with all-flash local and block storage devices, HPC can perform massive calculations in minutes instead of weeks or months.
- Cost: Faster answers mean less wasted time and money. Additionally, with cloud-based HPC, even small businesses and startups can afford to run HPC workloads, paying only for what they use and scaling up and down as needed.
- Innovation: HPC drives innovation across nearly every industry—it’s the force behind groundbreaking scientific discoveries that improve the quality of life for people around the world.
Organizations with on-premise HPC environments gain a great deal of control over their operations, but they must contend with several challenges, including
- Investing significant capital for computing equipment, which must be continually upgraded
- Paying for ongoing management and other operational costs
- Suffering a delay, or queue time, of days to months before users can run their HPC workload, especially when demand surges
- Postponing upgrades to more powerful and efficient computing equipment due to long purchasing cycles, which slows the pace of research and business
In part because of the costs and other challenges of on-premise environments, cloud-based HPC deployments are becoming more popular, with Market Research Future anticipating 21% worldwide market growth from 2017 to 2023. When businesses run their HPC workloads in the cloud, they pay only for what they use and can quickly ramp up or down as their needs change.
To win and retain customers, top cloud providers maintain leading-edge technologies that are specifically architected for HPC workloads, so there is no danger of reduced performance as on-premise equipment ages. Cloud providers offer the newest and fastest CPUs and GPUs, as well as low-latency flash storage, lightning-fast RDMA networks, and enterprise-class security. The services are available all day, every day, with little or no queue time.
Businesses and institutions across multiple industries are turning to HPC, driving growth that is expected to continue for many years to come. The global HPC market is expected to expand from US$31 billion in 2017 to US$50 billion in 2023. As cloud performance continues to improve and become even more reliable and powerful, much of that growth is expected to be in cloud-based HPC deployments that relieve businesses of the need to invest millions in data center infrastructure and related costs.
In the near future, expect to see big data and HPC converging, with the same large cluster of computers used to analyze big data and run simulations and other HPC workloads. As those two trends converge, the result will be more computing power and capacity for each, leading to even more groundbreaking research and innovation.